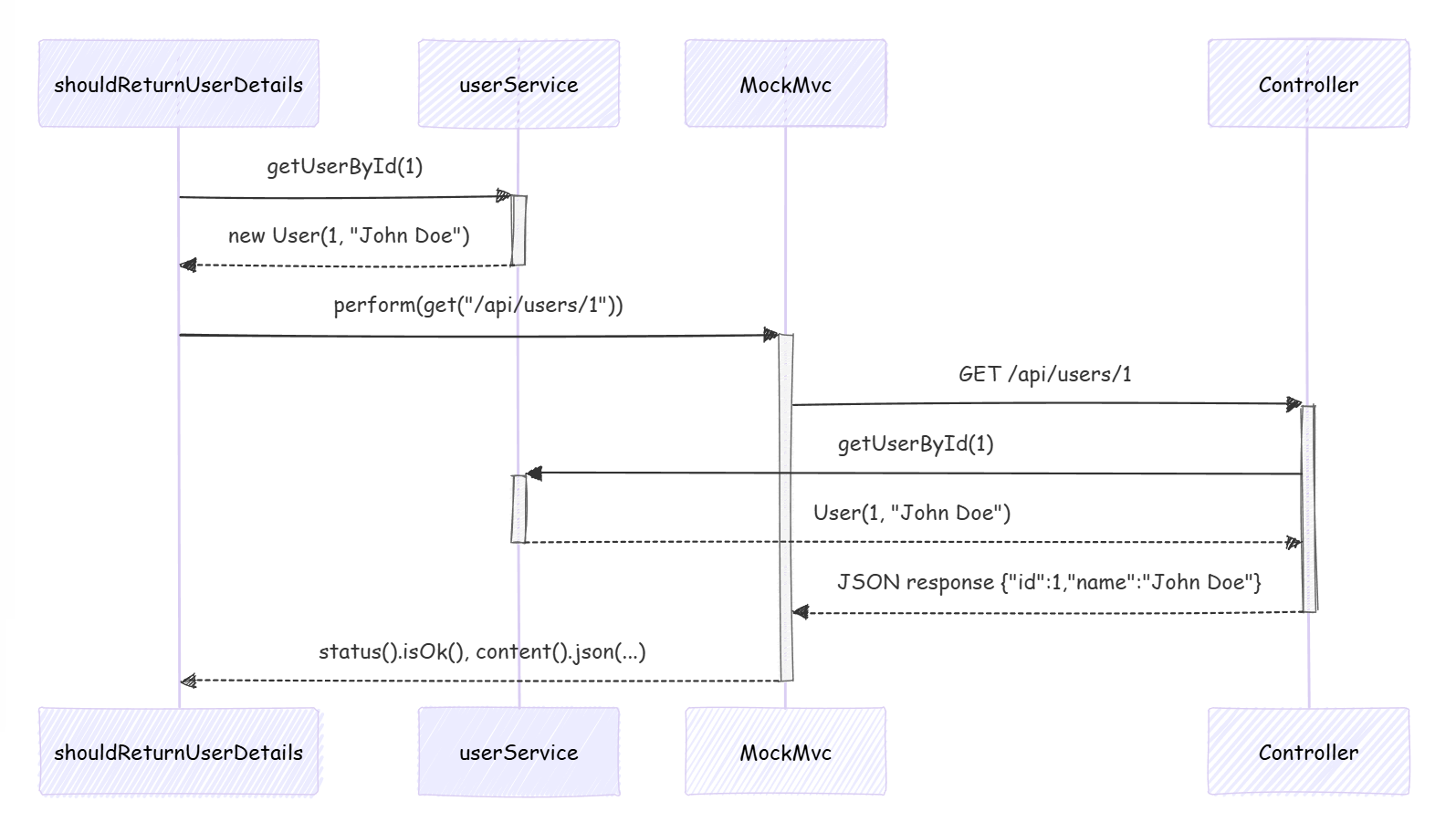
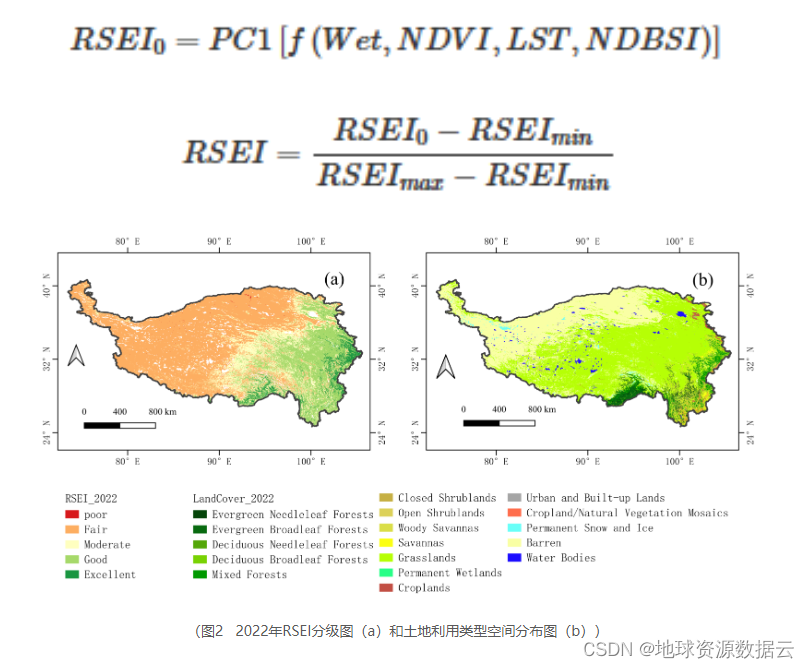
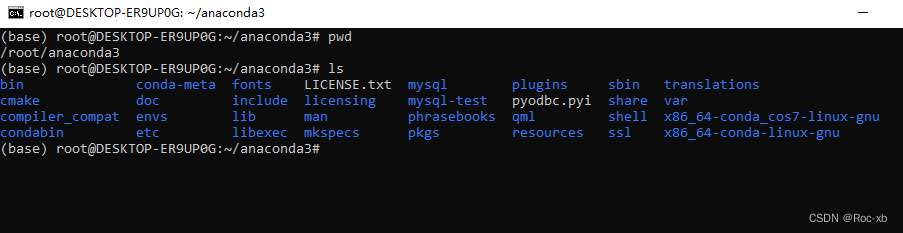
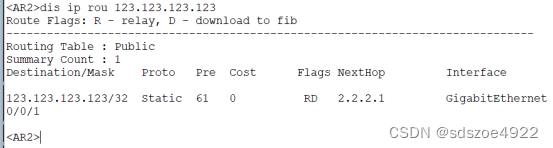
问题描述
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.'匹配任意单个字符'*'匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
解题思路
1. 定义状态
首先,我们定义一个二维的布尔数组 dp,其中 dp[i][j] 表示字符串 s 的前 i 个字符和模式 p 的前 j 个字符是否可以匹配。这里,“前 i 个字符” 是指字符串 s 从开头到第 i 个字符,同理适用于模式 p。
2. 初始化状态
初始化是动态规划解法中非常关键的一步。具体如何初始化:
- 基础情况:
dp[0][0]表示两个空字符串相匹配,显然是true。 - 处理模式中的星号
*:如果模式p的第j个字符是*,它表示前一个字符可以出现0次或多次。因此,dp[0][j]可以从dp[0][j-2]继承其值,意味着忽略*以及它前面的那个字符。
3. 状态转移方程
这是动态规划中核心的部分,我们需要为 dp 表中的每一个元素找到正确的值:
-
当
p[j-1]是'*':dp[i][j]可以是dp[i][j-2],这代表在模式中忽略这个*及其前面的字符。- 或者,如果字符串
s的第i个字符与模式p中*前的字符相匹配(或模式中该字符是.),那么dp[i][j]可以是dp[i-1][j]。这表示*代表的字符在字符串s中至少出现了一次。
-
当
p[j-1]是'.'或其他具体字符时:- 如果
p[j-1]是'.'或者s[i-1]等于p[j-1],那么dp[i][j]的值将依赖于dp[i-1][j-1],即去掉这两个字符之前的匹配状态。
- 如果
4. 实现细节
具体的实现中,我们需要遍历字符串 s 和模式 p,通过上述规则逐步填充整个 dp 表。最终,dp[m][n] 的值(其中 m 是字符串 s 的长度,n 是模式 p 的长度)将告诉我们字符串 s 是否能够完全匹配模式 p。
5. 示例
让我们通过一个具体的例子来进一步理解:
- 字符串:
s = "aab" - 模式:
p = "c*a*b"
这个例子中,我们通过动态规划的方法填充 dp 表,逐步确定每一个 dp[i][j] 的值。模式中的 c* 可以被解释为空,因为 * 表示 c 可以出现0次;接着 a* 表示 a 可以出现一次或多次,最后 b 匹配最后的 b。
代码实现
class Solution {
public:
bool isMatch(string s, string p) {
int m = s.size();
int n = p.size();
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
// 基础情况:空模式只能匹配空字符串
dp[0][0] = true;
// 处理类似 a*, a*b*, a*b*c* 等模式
for (int j = 2; j <= n; j++) {
if (p[j - 1] == '*') {
dp[0][j] = dp[0][j - 2];
}
}
// 填充dp表
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (p[j - 1] == '*') {
// 两种情况:不使用 '*' 或至少使用一次
dp[i][j] = dp[i][j - 2] ||
(dp[i - 1][j] &&
(s[i - 1] == p[j - 2] || p[j - 2] == '.'));
} else {
// 直接匹配或通过 '.' 匹配任意单个字符
dp[i][j] = dp[i - 1][j - 1] &&
(s[i - 1] == p[j - 1] || p[j - 1] == '.');
}
}
}
return dp[m][n];
}
};

![C语言力扣刷题1——最长回文字串[双指针]](https://img-blog.csdnimg.cn/direct/5d6ffa71658c4aec85a4f2a34031c3ae.png#pic_center)